ZooKeeper: shutdown Leader! reason: Not sufficient followers synced, only synced with sids
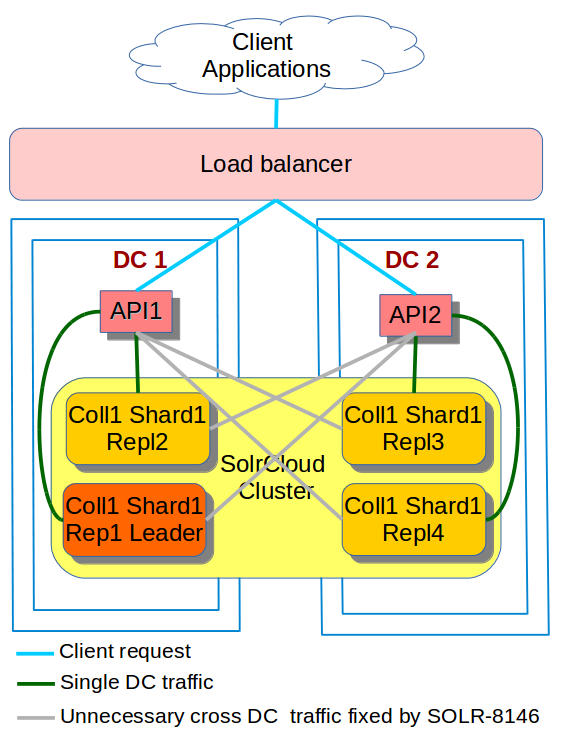
We have been running this cross DC SolrCloud cluster for over a year now and things have been working well for us.
A couple of weeks ago, In one of our non production environment, our monitoring system went mad as our ZooKeeper quorum shot itself down, leaving our SolrCloud cluster in a read-only state.![]()
The network seemed OK and no other system was affected.
However this was a non-production system, we spent some time investigating the issue by looking in the log and the system configuration files.
The ZooKeeper Leader
The log file on the ZooKeeper leader node showed that at the the time of the incident, we had:
[QuorumPeer[myid=K]/0.0.0.0:2181:Leader@493] - Shutting down [myid:K] - INFO [QuorumPeer[myid=4]/0.0.0.0:2181:Leader@499] - Shutdown called java.lang.Exception: shutdown Leader! reason: Not sufficient followers synced, only synced with sids: [ K ] at org.apache.zookeeper.server.quorum.Leader.shutdown(Leader.java:499) at org.apache.zookeeper.server.quorum.Leader.lead(Leader.java:474) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:799)
The above log entries revealed that in the allocated time (time-out T), no follower was able to sync data from the leader ZK node with myid K.
The leader (with id K not) having enough follower to maintain the quorum of 5, deliberately shot itself down.
The ZooKeeper Followers
The log entries on the followers are identical go as follow:
[myid:L] - WARN [QuorumPeer[myid=1]/0.0.0.0:2181:Follower@89] - Exception when following the leader java.net.SocketTimeoutException: Read timed out at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.read(SocketInputStream.java:152) at java.net.SocketInputStream.read(SocketInputStream.java:122) at java.io.BufferedInputStream.fill(BufferedInputStream.java:235) at java.io.BufferedInputStream.read(BufferedInputStream.java:254) at java.io.DataInputStream.readInt(DataInputStream.java:387) at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:63) at org.apache.zookeeper.server.quorum.QuorumPacket.deserialize(QuorumPacket.java:83) at org.apache.jute.BinaryInputArchive.readRecord(BinaryInputArchive.java:103) at org.apache.zookeeper.server.quorum.Learner.readPacket(Learner.java:153) at org.apache.zookeeper.server.quorum.Follower.followLeader(Follower.java:85) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:786) [myid:L] - INFO [QuorumPeer[myid=1]/0.0.0.0:2181:Follower@166] - shutdown called java.lang.Exception: shutdown Follower at org.apache.zookeeper.server.quorum.Follower.shutdown(Follower.java:166)
From the above entries, we can deduce that the followers were trying to sync data from the leaders at the same time and they threw java.net.SocketTimeoutException: Read timed out during the allocated time-out T
The ZooKeeper config
Now, looking at our configuration, we have among others the following lines:
tickTime=2000 initLimit=5 syncLimit=2
This means that the time-out T I was referring to in this blog is defined as
T = 2000*2= 4000ms = 4 sec
4 sec is definitely not enough for syncing SolrCloud config files data across multiple DCs.
The ZK configuration was clearly a default value that originally came with ZK and was never changed to reflect our deployment configuration
The fix
We changed the config to the one below
tickTime=4000 initLimit=30 syncLimit=15
Now, we are giving 60sec to each ZK follower node to sync data with the leader.
Other recommendations
– I would strongly recommend to read the ZooKeeper manual and understand the meaning of configuration options such as tickTime ,initLimit and syncLimit and check your ZK config files to make sure they are correct
– If your ZooKeeper server does not have an IPv6 address, make sure you add
-Djava.net.preferIPv4Stack=true
to your ZK start-up script. This will help avoid all sort of leader election issues (see [3] in the resources section below).
– By default, the RAM used by ZK depends on the one available the system. It’s recommended to explicitly allocate the heap size that ZK should use. This can be done by adding the following line into conf/java.env :
export JVMFLAGS="-Xms2g -Xmx2g"
You may want to change 2g to fit your need.
– It is a good idea to leave enough RAM for the OS and monitor the ZK node to make it NEVER swap!
Resources
- https://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_configuration
- https://zookeeper.apache.org/doc/trunk/zookeeperAdmin.html#sc_bestPractices
- http://lucene.472066.n3.nabble.com/Zookeeper-Quorum-leader-election-td4227130.html
- https://mail-archives.apache.org/mod_mbox/zookeeper-user/201505.mbox/%3CCANLc_9+5c-4eqGNx_mbXOH3MViiuBVbMLNPP3xhafQA2xQ=POg@mail.gmail.com%3E
- http://www.markround.com/ ( Thanks for figuring out the IPv6 issue )