Allowing SolrJ CloudSolrClient to have preferred replica for query operations
In the previous blog post,![]()
I discussed about how HTTP compression helped us improve solr response time and reduce network traffic in our cross DC solrCloud deployment.
In our deployment model, we have only 1 shard per collection and in term of content, all SolrCloud nodes are identical.
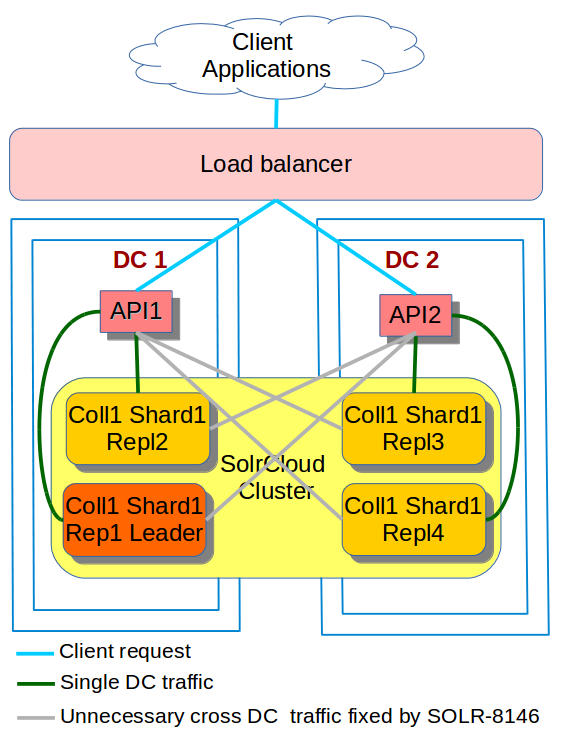
API and SolrCloud Traffic across two DCs
Let’s assume that:
- a request comes from the load balancer and lands on API1 in DC1,
- then API1 queries Solr Repl4 which is in DC2
- Response travels from DC2 back to API1 in DC1,
- the API1 finally sends response back to the client.
As stated earlier, all SolrCloud nodes have the very same content and are just replica of the same collection.
The question is: why should API1 go all the way to repl4 in DC2 to fetch data that is also available in repl1 and repl2 in DC1? There is certainly a better way.
To address this, we are proposing SOLR-8146 to the community
How it works
- Internally, the SolrJ client queries Zookeeper to find out the live replica of the collection being queried.
- SolrJ also acts as a load balancer. So, before querying Solr, SolrJ shuffles the list of replica URLs, and the first at the top of the list is used for querying. The second one is use only if the first one fails
- after the list is shuffled, we check whether the current request is a query operation or not
- If it’s a query operation, only then SOLR-8146 is applied by moving to the top of the list those URLs matching the specified Java Regular Expression . The pattern could be for instance an IP address or a port number etc. I would recommend you check the tests in the source code of the patch at SOLR-8146
Notes
- SOLR-8146 only deals with read or query operations. Any admin or update or delete operation will not be affected by the patch.
- SOLR-8146 changes only the SolrJ client behaviour
- SOLR-8146 comes into play if and only if the system property solr.preferredQueryNodePattern is set either by using the standard java -D command line switch or in java code System.setProperty()
- SOLR-8146 will still work no matter the number of collections deployed
- SOLR-8146 will still work no matter the number of shards deployed
- SOLR-8146 does not add to or remove nodes from the list of live solr nodes to query. it just re-order the list so that the one matching the specified pattern are first to be picked.
- One does not have to run SolrCloud across multiple DC in order to take advantage of SOLR-8146. There are many other use cases such as
- one could have a cluster running across multiple racks and prefer to have client API from rack1 talk to solr servers on rack1 only
- In a SolrCloud cluster, one may want one of the nodes to be used for analytics and manual slow queries or batch processing. SOLR-8146 would help keep a specific node from SolrJ queries.
- etc
Conclusion
SOLR-8146 brings more flexibility to the ways the SolrJ load balancer selects the nodes to query. This has many use cases.
Hopefully, it will be useful to others too.