Deploying SolrCloud across multiple Data Centers (DC)
Objectives![]()
Our objective is to deploy SolrCloud (5.X) across 2 DCs in active-active mode so that we still have all our search services available in the unfortunate event of a Data Centre loss.
Backgrounds
We used to run a Solr 3.x cluster in the traditional master-slave mode.
This worked very well for us for many years.
When Solr4 came out, we upgraded the cluster to the latest version of Solr, but still using the traditional master-slave architecture.
Why the move to SolrCloud?
There were many reasons behind this move. Below is a subset of them:
- The need for near real-time (NRT) search so that any update is immediately available to search,
- The ability to add more nodes to the cluster and scale as needed,
- The ability to deploy our search services in 2 DCs in active-active mode i.e. queries are simultaneously being served by both DCs,
- The ability to easily shard collections,
- The ability to avoid any single point of failure and make sure that the search platform is up and running in case one DC is lost.
The initial goal was to have our SolrCloud cluster deployed in 2 DCs meaning a ZooKeeper cluster spanning across 2 DCs.
As of the time of this writing, for Solr 5.3 and ZooKeeper 3.4.6 to work in a redundant manner across multiple DCs, we need 3 DCs, the 3rd DC being used solely for hosting one ZK node in order to maintain the quorum in case one DC is lost.
In summary, we have 3 private corporate DCs, connected with high speed gigabit fiber optic where the network latency is minimal.
Deployment
Note that we are well aware of the SOLR-6273 which is currently being implemented and the related blog entry at yonik.com .
We are also aware of SolrCloud HAFT
ZK Deployment:
- DC1: 2 ZK nodes
- DC2: 2 ZK nodes
- DC3: 1 ZK node
This is a standard ZK deployment forming a quorum of 5 nodes, spanning across 3 DCs
SolrCloud deployment:
In total 8 SolrCloud nodes, 4 in each of the two DC. DC3 having no SolrCloud node
- DC1: 4 SolrCloud nodes
- DC2: 4 SolrCloud nodes
- DC3: 0 (no) SolrCloud
Ingest Services deployment
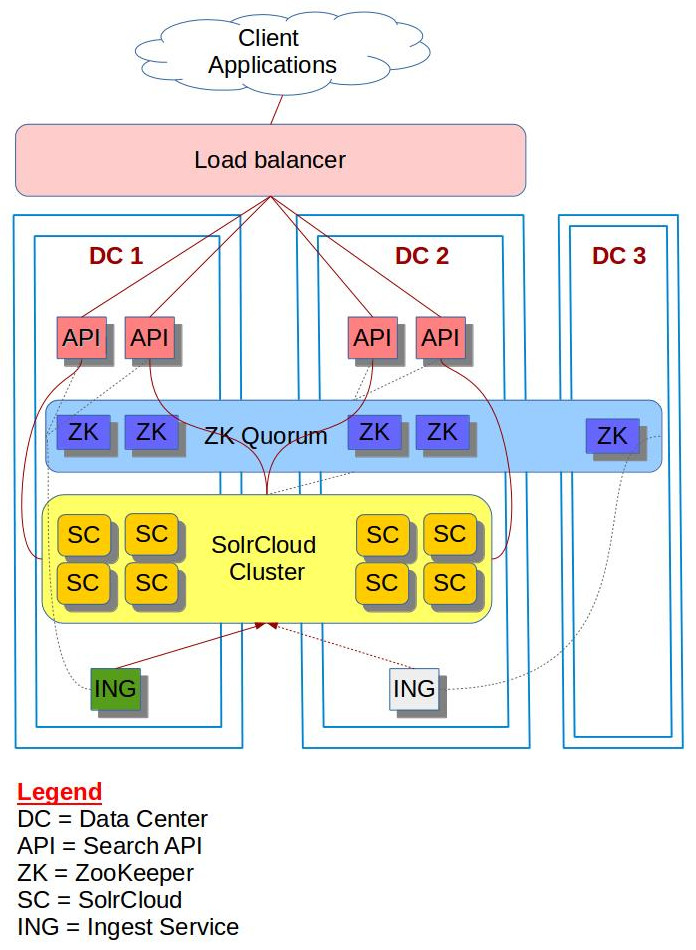
Cross DC SolrCloud Deployment architecture
The Ingest Service used to push data through to the SolrCloud cluster.
It’s build using SolrJ, so it talks to the ZK cluster as well.
- DC1 : 1 Ingest Service
- DC2 : 1 Ingest Service
- DC3 : 0 Ingest Service
Note that the ingest Services run in a round-robin fashion and at a given moment, only one of them is actively ingesting. The other one would be in standby mode and will be activated only if it’s the first to “acquire the lock”.
So, data flows from the active Ingest Service to the SolrCloud leader of a given collection regardless of the location of the Leader.
Search API deployment:
- DC1 : 2 API nodes
- DC2 : 2 API nodes
- DC3 : 0 (no) API node
This is API is built using SolrJ and is used by many client applications to search and suggestions.
Important note
In this deployment model, the killer point here is DC connectivity latency.
If there is high latency between the 3 DCs, this will inevitably kill our ZK quorum.
In our specific case, all 3 DCs are UK based and have fat pipe connecting them together.
Conclusion
During this process, we have come across many issues that we have managed to overcome them.
In the next blog post, I will be sharing with you the challenges we faced and how we addressed them.
Resources